Some days back, the creator of Python put up a tweet checking whether his understanding of agents was correct. Andrej Karpathy put up a reply under that tweet, comparing traditional engineering concepts to the agentic ecosystem.
The original tweet from Guido van Rossum can be found here and Karpathy’s reply is here.
This reply made me curious as to where the Harness would sit in this entire stack. Harness has been a buzzword for quite some time now and different people have different definitions for it. A simple Google search returns some blogs, but I don’t think there are a lot of write-ups or any universally accepted definition for it right now. Some of the blogs I liked and resonated with are linked at the end of this post.
According to me, the third component in the above comparison should be the Operating System itself, and it equates to the Harness, which makes the updated list look something like this:
| Agentic | ≡ | Traditional computing |
|---|---|---|
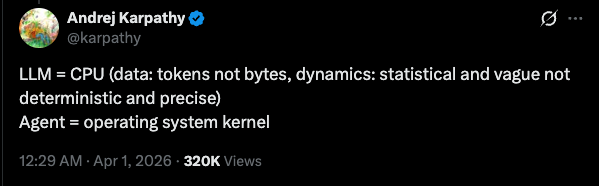
| LLM | ≡ | CPU — tokens not bytes; statistical and vague, not deterministic and precise |
| Agent | ≡ | Operating system kernel |
| Harness | ≡ | Operating system |

Equating the CPU and LLM makes sense — those are the actual brains or processors of the information, that is where information goes to be processed and a result is returned. The key contrast, as Karpathy senpai mentioned in his tweet, is that the input for an LLM is tokens and the system is not deterministic but stochastic. An Agent in my opinion is simply an LLM call wrapped in an infinite loop with the capability to act on different directives we call tools, where comparing the primitives makes the tool calls similar to your CPU’s instruction set. Similar to how an instruction set defines the fundamental capability boundary of a processor and a CPU can’t do anything not expressible through its instructions, the agent cannot take any action anything which is not composable with its tool set.

Now, similar to how an operating system kernel like Linux wraps this instruction set and implements the logic for OS booting, orchestrating instructions to enable common operations like connecting to a network, using I/O devices, and manipulating storage via system calls — the agent, with its system prompt and tool configuration, exposes different sets of functionality. This is what we may call a Harness. This separation matters for the same reason operating systems matter — they help you build software without needing to mess with the core runtime again and again. Similarly, you can build a harness once with your own opinions and then keep adding/removing agents or experimenting with different models all in one place without needing to change this setup or its integrations in other software you are building.

A Harness would also include setting up other important things like plugging in data sources, MCPs giving the agent additional capabilities and most importantly your own opinionated ways to manage context — for example how Claude Code and OpenAI Codex manage context via sessions and use compaction when you hit your token limit and Sourcegraph’s AmpCode uses threads and handoffs. All three of these tools are great harnesses with mass adoption among the developer community and they run the same frontier models (maybe Claude Code and Codex use different ones but you can always expose Codex as an MCP to Claude Code :p — ref for those who might be interested) and Amp has different modes — Smart for Opus 4.6 and Deep for Codex (at the time of writing this). The only difference between these three coding tools and many others in the category is the way they choose to set up shop around their agent, resulting in different harnesses.
Now, the distinction I am trying to paint by this example might not be very clear via an example of these three because they are not just different harnesses but different agent/kernel implementations also, since they have their own implementation of basic tools available to the LLM when it is running in a loop. But all three of these tools publish their own SDKs which I believe is their attempt to be the core agent/kernel in the vast ocean of agentic software tools that are about to emerge. For example, if you had to build a PR review agent for your team which is oddly specific to your team’s practices and the 5 micro-services, 2 dashboards and 3 libraries your team maintains — with the help of this SDK you would only need to set up your own harness and not the agent, it will be taken care of by the SDK you are using. You’d only need to set up the review rules as prompts or plugins, maybe integrate treesitter or some LSP and some remote sandbox environment like modal or E2B, and then integrate this software with the platform where you manage code to trigger the reviews and your communication systems like Slack, Discord, etc. to consume the output. You can then always use your imagination to expand the scope and build systems and other software on top of this to help in other areas. This particular example was more about writing your own operating system — obviously, there are tools which sell you code review functionality out of the box and that would be the same as buying your operating system from Microsoft or Apple, as opposed to writing one yourself, similar to how computer scientists used to do before companies started selling operating systems as commodities.
Obviously the above definitions I talked about are not exactly a 1:1 mapping and there are grey areas where the above explanation also falls short or becomes ambiguous, but this is my mental model at the moment.

Reading/References
A list of some other opinions and writing I liked and found interesting.